



Mocking on Steroids: Testing Positive and Negative Criteria With Fuzz Data
To test an application with dynamic inputs, you would usually have to compile and run it first. But with embedded software, you often have the problem that it only runs on specific hardware or that the application requires input from external sources. For this reason, mocking/simulating these dependencies is needed for DAST, IAST, or fuzzing.
A bare-bones approach to testing embedded systems can also be mocking for the hardware-dependent functions to return static values. However, this setup is basically blind, as it lacks runtime context, causing it to miss many possible behaviors, resulting in comparably low code coverage.
As described above, a more accurate method for embedded security testing is by mock testing your embedded systems with fuzz data. This allows you to dynamically generate return values for your mocked functions, so you can make use of the magic of feedback-based fuzzing to simulate the behavior of external sources under realistic conditions. Also, this approach lets you cover both positive and negative test cases during your tests. If you have the resources, I would always recommend combining different DAST, IAST, and fuzzing approaches.
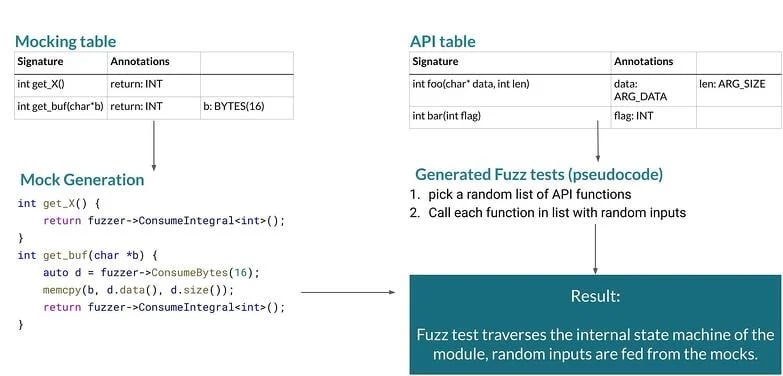
Two Excel sheets can be enough to generate a fuzz test that will achieve high code coverage while using fuzz data to simulate the input from outer sources
The Secret Sauce to Fuzzing Embedded Software: Instrumentation
One of the reasons why modern fuzzing technology is so effective is that it can leverage feedback from previous test inputs to increase code coverage. To achieve this, the source code has to be instrumented using sanitizers. A sanitizer is a software library used to compile code with the goal of making programs crash more often. By receiving information about the program under test from these sanitizers, the fuzzing engine can constantly craft more effective test inputs.
Leveraging the API Documentation to Generate Fuzz Tests
You will most likely need some form of structured input to automatically generate your test harnesses. To determine what kinds of input may be suitable for testing, use the documentation of the Public API. In my experience, most software teams that work on embedded hardware have such documentation stored as a CSV or Excel table. This documentation can be used to automatically create sophisticated fuzz tests without any further adaptations.
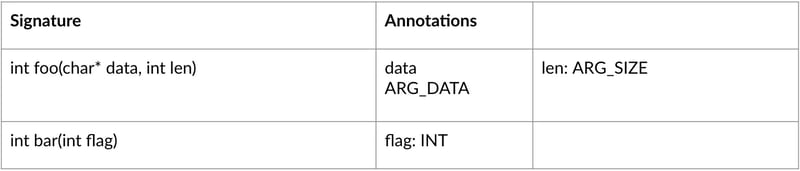
Your fuzzer then starts by calling functions from your Public API documentation file in random order, with random parameters. Through instrumentation, the fuzzer can then gather feedback about the covered code. Based on this feedback, it can actively adapt and mutate the called functions and parameters to increase code coverage and trigger more interesting program states. This setup will allow you to generate test cases you might not have thought of that can traverse large parts of the tested code.
Industry Standards for Embedded Software Testing in AutomotiveThe automotive industry is subject to many industry norms. Many of them, such as ISO/SAE 21434 or WP. 29, include requirements for software security testing. A large number of these norms recommend integrating modern fuzz testing into the development process as a measure to comply with their requirements. Especially ISO/SAE 21434 has presented the automotive industry with many new challenges in recent years. Based on our experience with customers, my colleagues created an overview of how modern fuzzing technology can help automotive software teams become ISO 21434 compliant while building more secure software.
|
3 Reasons Why You Should Fuzz Embedded Systems
In my experience, fuzzing is one of the most effective ways to test embedded systems. Especially because the margin of error is very small in many embedded industries, as software defects do not only affect the functionality of systems, they can have a physical impact on our lives(e.g., in automotive brake systems).
1. Increased Code Coverage
By leveraging feedback about the software under test, modern fuzzers can actively craft test inputs that maximize code coverage. Apart from reaching critical parts of the tested code more reliably, this enables highly useful reports that let dev teams know how much of their code actually was executed during a test. This reporting may be helpful in identifying which parts of their code need additional testing or more inspection.
2. Detecting Memory Corruption Accurately
Uncovering memory corruption issues is one of the strong suits of feedback-based fuzzing which is highly relevant for memory-unsafe languages such as C/C++(nonetheless, fuzz testing is also very effective at securing memory-safe languages). By feeding embedded software with unexpected or invalid inputs, modern fuzzing tools can uncover dangerous edge cases and behaviors related to communication with the memory.
3. Early Bug Detection
Feedback-based fuzzing tools can be integrated into the development process to test your code automatically as soon as you have an executable program. By leveraging the bug-finding capacities of fuzzing early, you can find bugs and vulnerabilities before they become a real problem.
Example: If you find a bug in a JSON parser during unit testing, you can most likely fix it in a couple of minutes. This is relatively easy compared to fixing a crash that was possibly caused by a specific user input that only affects one certain component. So do yourself a favor and fix the bugs before they pop up in production.
Enterprise Best Practice to Deal With Complexity: CI/CD-Integrated Fuzz Testing
I recommend CI/CD-integrated fuzz testing for enterprise projects, as it allows you and your team to fuzz your code automatically at each code change. Ideally, you would implement such a testing set-up early in the development process to avoid late-stage fixes and to speed up the development process. I think Thomas Dohmke, CEO of GitHub, put it best when he said that modern fuzzing tools are "like having an automated security expert who is always by your side."
Anyways, if you want to find out more about how you can set up fuzz testing for large automotive projects, you can book a personal demo with one of my colleagues or check out our product page.
