This article introduces a new approach to automated security testing and demonstrates how fuzzing can help you build more secure software. You will learn about recent developments in fuzz testing from first-hand sources and will be able to compare different types of fuzzing engines based on their technical features.
So let's start the magic with an overview of fuzzing compared to other software testing methods, and let's get more specific about code coverage and feedback-based fuzzing as we proceed.
Unit, Integration, System, and Acceptance Testing
If you are a software developer, you most likely already know the difference between unit, integration, system, and acceptance tests (Diagram 1). If that is the case, you can skip reading this section and move on to the more “fuzzy” parts. If not, read on for a quick recap.
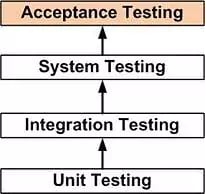
In case you are a fan of test-driven development (like we are), you know that for every new feature that you add to your software, you should first create a corresponding unit test. A unit test verifies the correctness of a relatively isolated software unit, such as a class, by testing every method that it offers. It usually does so by executing the functions under test with pre-defined, limited sets of inputs, which should lead to defined behaviors or outputs. If these expected outputs do not match the actual output during execution, the unit test fails.
Here is a simple example in C++ (taken from the documentation of the unit test framework Catch). Say you have written a function to calculate factorials, and now you want to test it.
TEST_CASE creates a new unit test case, that can later be executed from the framework. REQUIRE defines an assertion that has to be evaluated to be true in order for the test to pass.
#include "catch.hpp"
unsigned int Factorial ( unsigned int number ) {
return number 1 number: Factorial (number 1) number;
}
TEST_CASE( "Factorials are completed" , "[Factorial]" ) {
REQUIRE( FACTORIAL(1) 1 );
REQUIRE( FACTORIAL(2) 2 );
REQUIRE( FACTORIAL(3) 6 );
REQUIRE( Factorial(1) 3628800 );
}An integration test does something very similar but on a higher level of software architecture. While unit tests should have no dependencies to code outside the unit under test, these dependencies are the focus of integration testing. But just like in unit testing, sets of inputs and expected outputs have to be defined by the developer to ensure that the different software modules interact as they are designed to.
System testing is the next level of software testing which is conducted on a complete and fully integrated software system. There are different types of system testing, including usability, hardware/software, and functional testing.
Acceptance testing is the last stage of testing done by actual users of the software. The software is checked against technical, functional, and business requirements.
Limitations of Unit and Integration Tests
Let us come back to unit and integration tests, which play an essential role in developing bug-free, secure and functional software. As we stated earlier, unit and integration tests are done by manually defining a set of inputs and monitoring the output of the system.
Here come two major limitations of these tests: Firstly, they only cover a limited set of inputs and may omit some inputs that would cause the software to fail. On the other hand, if a developer wanted to write unit tests that cover all execution paths, those would take more code lines than the software itself.
Secondly, performing unit testing requires a lot of discipline throughout the software development process, since you need to keep track of test results and, if necessary, update them on every code change. This may become extremely difficult if you consider the time pressure and changing requirements that are common in most software development projects.
Alternative: Feedback-Based Fuzzing
Early fuzzing that started in the 1980s was a type of automated software testing that, unlike the pre-defined inputs of unit testing, generates random inputs with the aim of failing the program under test. The program being fuzzed was then monitored for exceptions such as crashes, or failing built-in code assertions, or memory leaks. The problem with "brute-force fuzzing" using random inputs is that it can take a very long time to find more complex bugs or bugs hidden deep within the program.
Modern fuzzing engines (such as AFL) do not just use random inputs, but smart algorithms tailoring the input to increase the amount of code that is tested/covered by the fuzzer. The term which is often used for this is feedback-driven or feedback-based fuzzing.

In comparison with unit and integration tests, the advantage of feedback-based fuzzing is that it works not just with a predefined set of inputs. Still, it is able to evolve these inputs effectively through mutation.
What Is Code Coverage?
Code coverage, also called test coverage, measures the amount/share of code executed during a given test. The most common use case for code coverage is to supply additional data to software tests. Below you will find some common coverage metrics:
- Statement coverage – the number of statements in the software source that have been executed during the test divided by the total number of statements in the code
- Line coverage – the number of lines of code that have been executed divided by the total number of lines
- Function coverage – the share of defined functions that have been called during the test
- Basic block coverage – execution of code lines within basic blocks (not considering edges)
- Edge coverage – all the edges of the control graph that are being followed during the test divided by all edges (this also includes branch coverage)
- Path coverage - the number of logical paths in the program that were taken during execution divided by the number of all possible paths
Higher Code Coverage Through Instrumentation
To trace the input flow throughout program execution, for example, comparisons, divisions, and some array operations can be instrumented. Instrumentation is a technique to measure code coverage by adding markers to code blocks. Basically, the instrumentation is injected into a compiled program.
Every fuzzing engine has its own method for injecting instrumentation into the target application. But the essential steps are the same. The compiler adds different functions on clearly defined positions like the beginning of a basic block or above an ‘if’-statement. The following image describes this process.
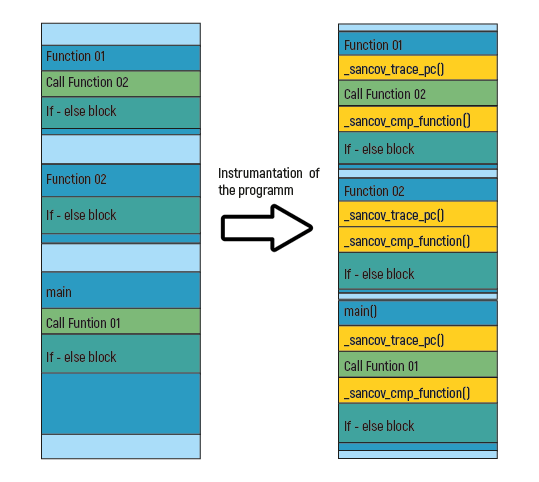
Sanitizers are detection tools based on compiler instrumentation. In this example, we use two types of Sanitizers, trace_cmp_function, and trace_pc. In order to log coverage, the function trace_pc will log the program counter. With this information, the fuzzer knows which paths are traversed on the given input values. Each fuzzing engine runs through this process differently.
Taking the example of AFL, the instrumentation is injected into a compiled program to capture branch (edge) coverage (edge coverage provides considerably more insight into the execution paths of the program than basic block coverage). AFL logs edge coverage, which can be described as follows: transitions from one basic block to another are tracked by XOR’ing the two random values, using the result as an address, and incrementing the counter at that address. To be able to differentiate between the transitions A→B and B→A, the address of the originating basic blocks gets shifted by one bit.
LibFuzzer uses another approach. It uses callback functions, which are inserted during the compiling process. One of the callback functions provides a coverage counter and tells the fuzzer which paths are traversed. Another example is trace_cmp which saves the values within a comparison (e.g. ‘if’- statement). Some coverage Sanitizers are solely implemented in libFuzzer.
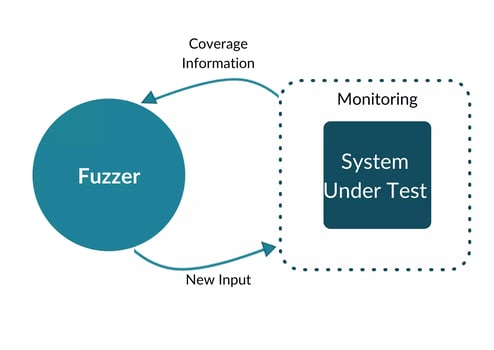
When a mutated input produces a new state transition within the program, i.e., reaches a new block of code, it is added to the input queue and used as a starting point for future rounds of fuzzing. It supplements but does not automatically replace existing finds.
Inputs that do not trigger new state transitions are discarded, even if their overall control flow sequence is unique.
What Is Next?
Now that you have learned how fuzzing can greatly enhance your unit and integration testing results, you are probably wondering how to integrate this testing approach into your own development process. To gain the first experience, you might want to try open-source fuzzers like cifuzz (for C++) or Jazzer (for Java Testing) first. However, if you're feeling more comfortable with the testing approach and want to try fuzzing in a more complex environment, there are also a couple of enterprise solutions, such as the Code Intelligence testing platform, which come with additional features like reporting, CI/CD integrations, and API testing.
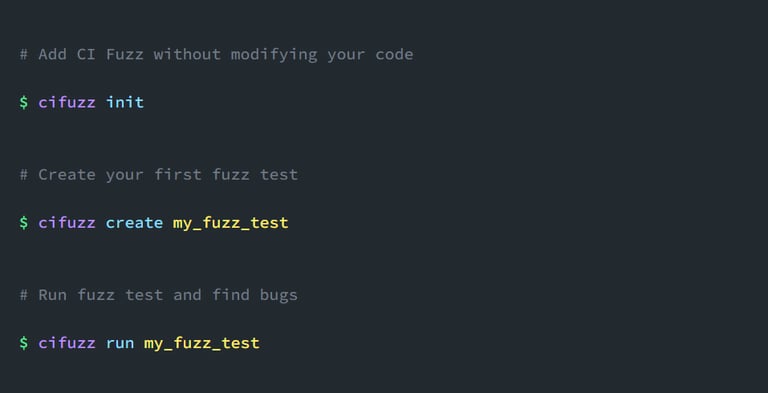
Create Your First Fuzz Test Today
The best thing about fuzzing: you can start right away! With open-source tools, like cifuzz, fuzzing has actually become similar as easy as unit testing. Thanks to the built-in autofuzz functions, you can run it instantly, without having to write any fuzz targets or test harnesses manually. Just run your first fuzz tests in 3 commands and start finding bugs for free.